These are some notes from HF’s Diffusion Models live event.
I was mainly interested in future opportunities (as of Nov 2022) of Stable Diffusion, so I only took notes on these points.
Devi Parikh: Make-A-Video
How does make-a-video work at a high level?
- the input can be text OR an image
- “uses images with text description to learn what the world looks like and how often it is described”
- “also uses unlabeled videos to learn how the world moves”

- text to audio generation
Justin Pinkney: Beyond Text
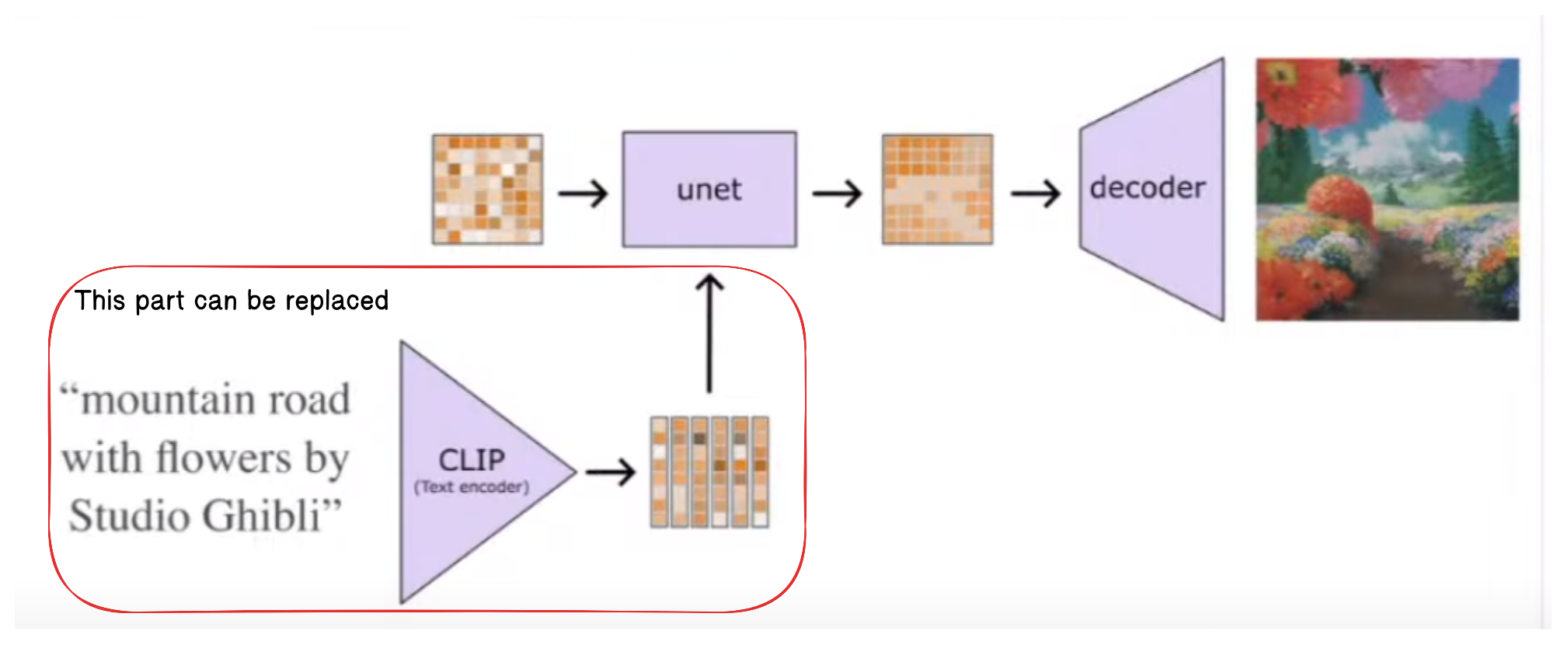
Text isn’t always enough
Stable diffusion’s text encoder can be replaced with other things for interesting effects (eg. CLIP image encoder)
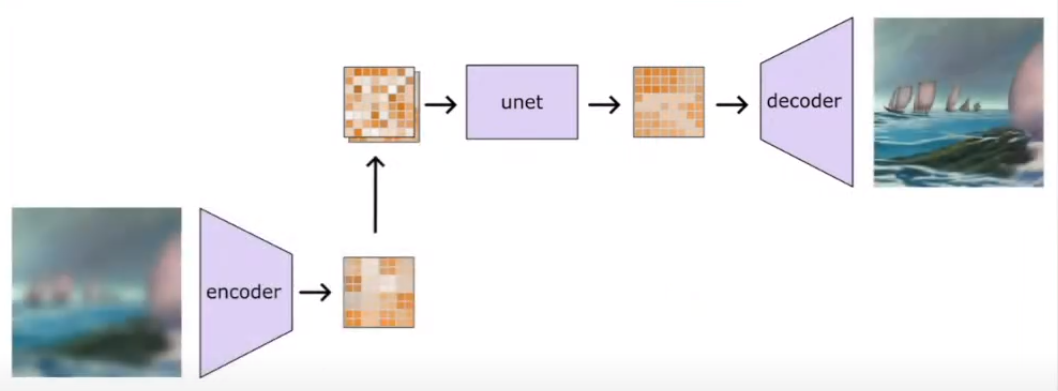
Experiments with face variations

- CLIP encoder that takes 2 encodings, 1 that is focused on the face region and the other where the face is masked out
- 2 embeddings generated and fed into unet
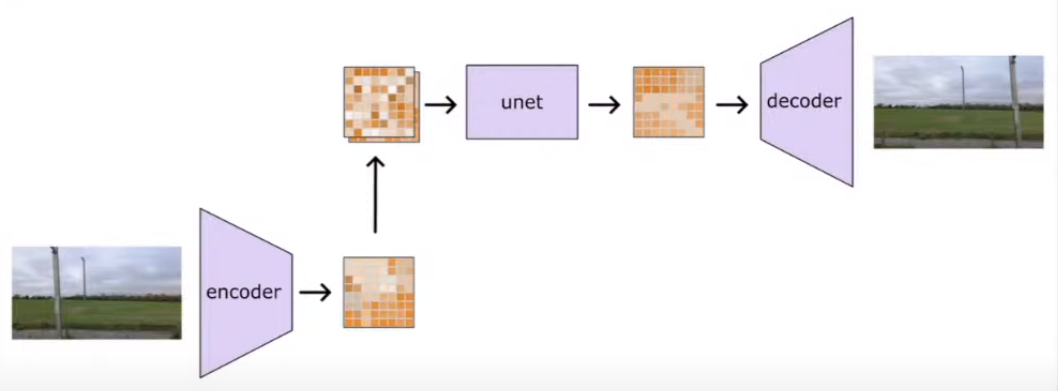
Super Resolution
Take a lower resolution image and turn it into a high resolution image
- Takes a whole image as an input and passed to unet
- decoder turns it into a higher resolution
Next Frame Prediction
- Takes a video and treats it as a sequence of frames
- Take a network and use it to predict the next frame